Some benchmarking of "camp get", on Debian amd64/Linux.
We are comparing:
| camp | The code as of 2009-03-14, compiled with GHC 6.11.20090308. |
| darcs1 | The 1.0.9 darcs release, compiled with GHC 6.11.20090308. Had to make some minor tweaks (fix how openFd is called, turn off -Werror, force use of base-3.0.3.0, link with the containers package) to get it to build, but nothing that will affect the results. Based on the user agent, it is using libcurl to download over HTTP. |
| darcs2 | The 2.2.0 darcs release, compiled with GHC 6.11.20090308. Based on the user agent, it is using libcurl to download over HTTP. |
| git | Version 1.5.6.3, from the Debian package version 1:1.5.6.3-1.1. |
We use 6 repositories:
| darcs1 | A "darcs get" of my local GHC HEAD repo, up to the "2009-03-13" tag. It contains 20,316 patches, which are composed of 369,163 primitive patches. |
| darcs1hashed | is "darcs2 get --hashed darcs1 darcs1hashed" |
| darcs2 | is "darcs2 convert darcs1 darcs2" |
| camp | is "darcs2camp darcs1; rm -r darcs" (darcs2camp creates and uses the "darcs" directory while converting) |
| campfrag | is "campfragment camp campfrag" |
| git | is "git-darcs-import darcs1 git; cd git; git update-server-info" |
The campfrag repo is a worst-case camp repository: In the patch file, there is a random number (between 5000 and 6000) of "x"s between each two megapatches. This means that to download the patches camp needs to make a separate request for each patch.
We do seven tests:
| camp | Get the "camp" repo with camp. |
| campfrag | Get the "campfrag" repo with camp. |
| git | Get the "git" repo with git. |
| darcs1 | Get the "darcs1" repo with darcs1. |
| darcs2.darcs1 | Get the "darcs1" repo with darcs2. |
| darcs2.darcs1hashed | Get the "darcs1hashed" repo with darcs2. |
| darcs2.darcs2 | Get the "darcs2" repo with darcs2. |
Each test is done on the local filesystem, and over HTTP to localhost. When doing a test, we do it once (ignoring the results) to warm up the cache, and then five more times in which we record various numbers using "/usr/bin/time" and (with the obvious exception of git) the GHC RTS.
First, lets look at the elapsed time of a local get:
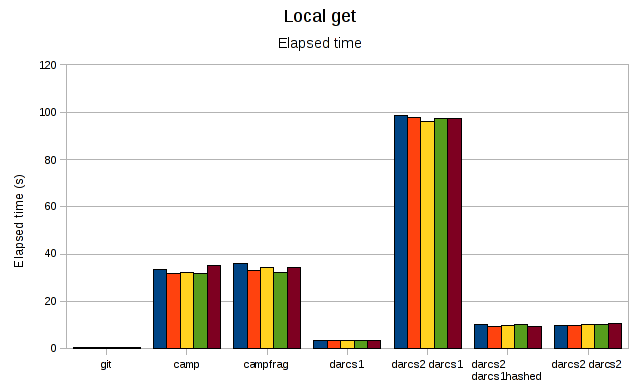
Git is blindingly fast here at under a second, while camp clocks in at 30-35s (regardless of whether or not the repo is fragmented). I haven't checked the source, but I'm pretty sure that darcs1 is cheating (copying the pristine from the remote repo in a way that will leave you with an inconsistent repo if someone is pulling a patch into the remote repo at the same time), but darcs2 pulls the same trick in a safe way for the last 2 columns. Meanwhile, darcs2 plays by the rules when getting the darcs1 repo, but takes more than a minute and a half to do so.
Now lets look at the peak memory usage, as recorded by GHC's RTS (so no figures for git):
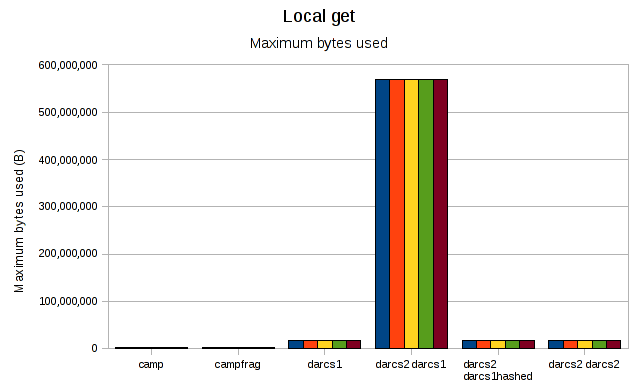
Darcs2 needs almost 600M for the darcs1 repo, which makes the rest of the graph almost unreadable. Regraphing without it:
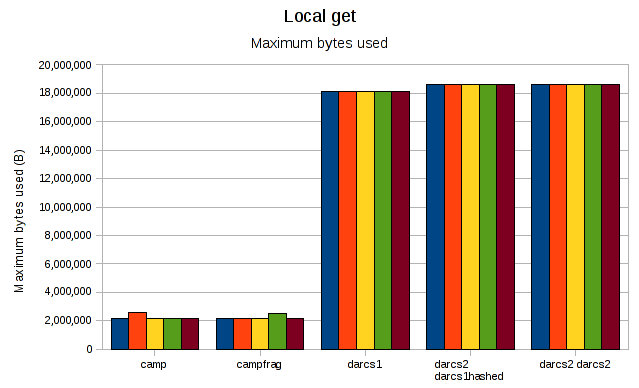
and we can see that camp's memory usage (which includes actually applying the patches) is well below that of both darcs1 and darcs2 (which are not applying the patches here).
Now let's look at getting over HTTP. First, elapsed time:
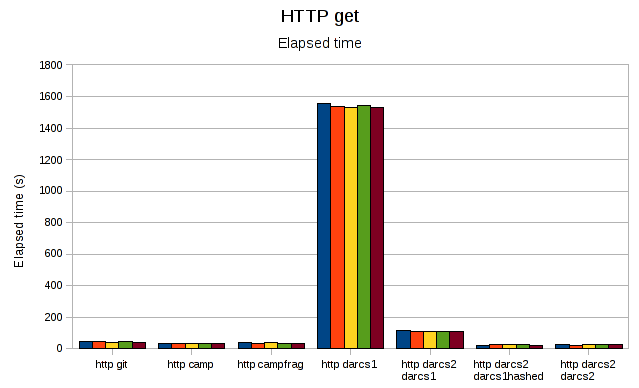
In this case, darcs1 takes more than 25mins, which makes the graph unreadable. Without it:
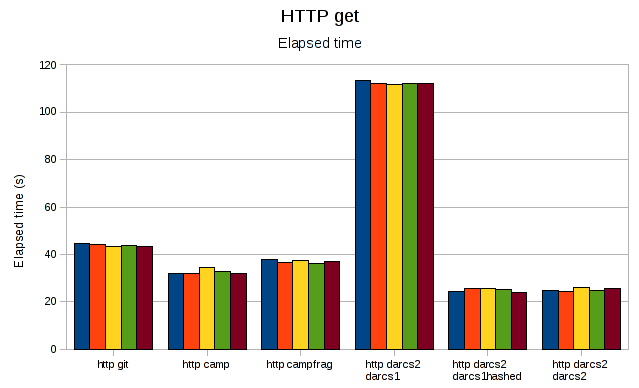
Interestingly, git no longer has an advantage. darcs2 (when not applying patches) still has the edge on camp, and there is more of a difference between a compact and fragmented camp repository. As before, darcs2 getting an old-style darcs1 repo (and therefore applying patches) is significantly slower.
Looking at the memory usage:
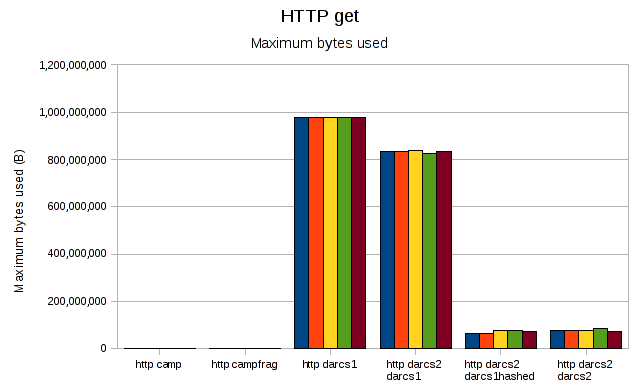
both darcs1 and darcs2 now use 800M-1G when getting the old-style darcs1 repo. Regraphing without them:
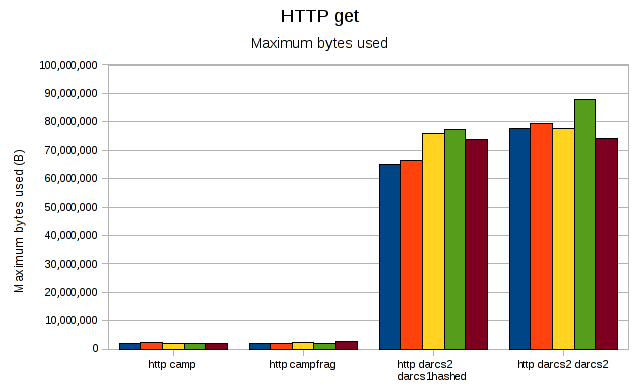
Darcs2's memory usage is significantly higher than it was when getting locally, but camp's is unchanged.
There are many shortcomings of these tests. First, camp is not complete: The things most likely to make a difference are that it doesn't do all the sanity checking that it should, and it doesn't look to see if there are unresolved conflicts in the repo. I don't think that these will make a significant difference, and I'm not sure how much sanity checking darcs does either, but it's hard to be sure without implementing and testing it.
I have made no attempt to tune apache, git, darcs1 or darcs2. Note that camp, darcs1 and darcs2 are all using the same libcurl and were all compiled with the same version of GHC, though. Darcs2 was not built to use HTTP pipelining, and according to the cabal file it needs a newer version of libcurl than Debian has to do so. However, given the small difference between getting the camp and campfrag repos, it seems unlikely that it would have made much difference.
The HTTP gets were extremely low latency and high bandwidth, which means that the results only show the differences in the algorithm, not the effect of actually downloading over a normal internet connection. It would be interesting to simulate a normal connection and see what the results are; I expect it would indicate that camp would benefit from pipelining when getting fragmented repos.